🚀 PREZZI AGEVOLATI fino al 29 giugno alle 23:59 ⚠️ Ultimi posti disponibili per i nostri corsi intensivi SSM 2026 ⚠️
📌 29/06 h. 20:00 Partecipa al nostro evento online "Quanti punti ti servono per entrare dove vuoi?"
Corsi SSM
Manuali
Preparazione esami
Simulazioni
L’esperienza Testbusters al tuo fianco per entrare nella specializzazione che sogni
Peer4Med è la soluzione di Testbusters dedicata a studenti e studentesse di medicina
Crediamo nella formazione Peer-to-peer: un metodo migliore di apprendere e di insegnare, più individualizzabile e coinvolgente, che coniuga esperienza diretta, competenza e passione.
La nostra squadra è composta esclusivamente da specializzandi e specializzande che hanno brillantemente superato il test di specializzazione di medicina

Preparati al Concorso SSM con Peer4Med
Preparati al Concorso SSM con Peer4Med
Corsi, manuali, quiz: tutti i nostri materiali sono ideati per massimizzare i tuoi risultati. Ti accompagneremo in un percorso personalizzato, chiaro ed efficace, con l'obiettivo di farti entrare nella scuola di specializzazione dei tuoi sogni
Corsi SSM 2026
Ti laurei a luglio e non sai come prepararti per SSM? Scopri i nostri corsi intensivi per il Concorso SSM 2026!

Corsi SSM 2027
Impara un metodo di studio efficace e i trucchi per superare il Concorso SSM 2027 ed entrare in scuola di specializzazione.

Corsi SSM 2028
Sei al V anno di medicina? Preparati al Concorso SSM 2028 con i nostri corsi biennali.

Manuali SSM
La nostra proposta editoriale si basa sull'analisi statistica delle prove ufficiali, per una preparazione realmente orientata al test

Preparazione esami universitari
Affronta la facoltà di Medicina e Chirurgia con un metodo strutturato: i nostri pacchetti per la preparazione degli esami ti permetteranno di superare efficacemente anche i più temuti!
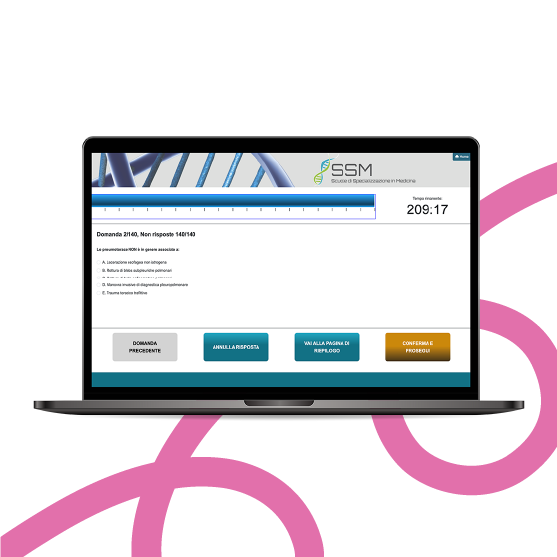
Simulatore SSM
Simulazioni SSM con correzioni commentate e interfaccia identica al test ufficiale. Prova i nostri quiz SSM, puoi crearne anche su misura!
Concorso MMG
Affronta con sicurezza il Concorso MMG: il nostro kit combina teoria, pratica e simulazioni test MMG per una preparazione strategica

Corsi e Manuali per la Formazione e la Pratica Medica
Corsi e Manuali per la Formazione e la Pratica Medica
Scopri le nostre risorse dedicate alla formazione medica per studenti e medici in formazione, perfette per tirocini, guardie e lezioni in reparto. Integra tutto con la formazione continua che ti serve davvero per esercitare la professione medica!


Hai dubbi su quale sia il percorso giusto per te?
Troviamo insieme la strada corretta per te: lasciati guidare dai nostri docenti e studenti Peer4Med!

Le nostre storie di successo
Ogni docente Peer4Med ha superato il test SSM ed è oggi uno specializzando. Questo garantisce aggiornamento costante e la capacità di offrire una didattica pratica e orientata al risultato.

Cecilia Marcolin
Specializzanda in Cardiologia
1^ classificata
Test SSM 2020

Monica Ianniruberto
Specializzanda in Cardiologia
14^ classificata
Test SSM 2020

Fabiana Bisceglia
Specializzanda in Cardiologia
22^ classificata
Test SSM 2023

Carlo Gigante
Specializzando in Cardiologia
Primi 100 classificati
Test SSM 2020
Guide didattiche e ultime news sui test


